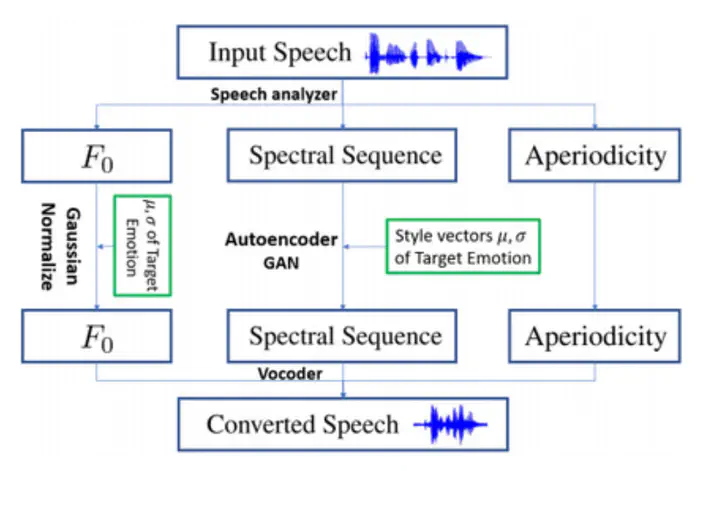
We aim to implement a Neural Network system for generating the speech corresponding to a piece of text, with a small caveat: the generated speech should be directed towards an input emotion, such as angry, sad, happy, shocked etc. The preliminary idea is to join two networks: the first one for a general text to speech conversion and the second one for adding emotions to the waveform output by the first network. Our initial plan is to have the first network (text to speech) take as input, a voice sample and generate the output that sounds similar to the input voice sample.
Drumil Trivedi
Quantitative Researcher at AlphaGrep Securities
My research interests include Natural Language Processing, Robotics and Speech Recognition.
