Abstract
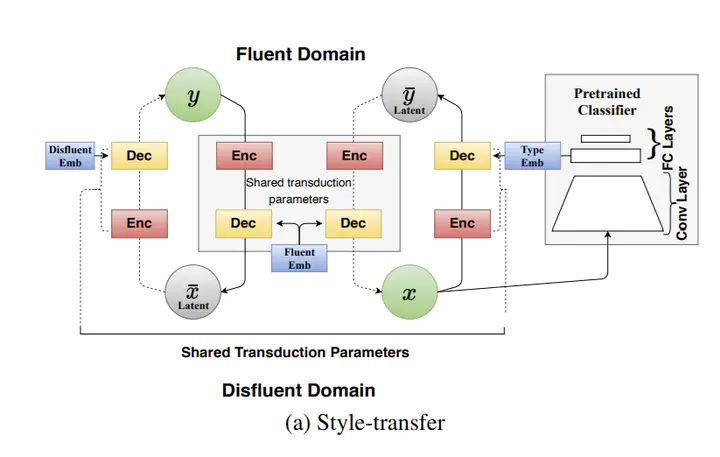
Spoken language is different from written language in its style and structure. Disfluencies that appear in transcriptions from speech recognition systems generally hamper the performance of downstream NLP tasks. Thus, a disfluency correction system that converts disfluent to fluent text is of great value. This paper introduces a disfluency correction model that translates disfluent to fluent text by drawing inspiration from recent encoder-decoder unsupervised style-transfer models for text. We also show considerable benefits in performance when utilizing a small sample of 500 parallel disfluent-fluent sentences in a semi-supervised way. Our unsupervised approach achieves a BLEU score of 79.39 on the Switchboard corpus test set, with further improvement to a BLEU score of 85.28 with semi-supervision. Both are comparable to two competitive fully-supervised models.
Drumil Trivedi
Quantitative Researcher at AlphaGrep Securities
My research interests include Natural Language Processing, Robotics and Speech Recognition.